
تنظیم عملکرد (Performance tuning) در دیتابیس
چند وقت پیش در مورد تنظیم عملکرد در دیتابیس تحقیقی انجام دادم و در اینجا میخوام در موردش بنویسم. در ادامه هر کدوم از موضوعات زیر به صورت مختصر مورد بررسی قرار میگیره.
- تعریف تنظیم عملکرد
- مروری بر مبحث دیتابیس
- مقایسه SQL و NoSQL
- Performance tuning از دید کلی
- Performance tuning در SQL در سطح نرم افزار
- Performance tuning در SQL در سطح سخت افزار
- Performance tuning در NoSQL در سطح نرم افزار
- Performance tuning در NoSQL در سطح سخت افزار
- Performance tuning در شبکه
- آیا Performance tuning همیشه انجام میشه ؟
تعریف تنظیم عملکرد
تنظیم عملکرد (Performance tuning) فرایند تجزیه و تحلیل و بهینه سازی یک سیستم (دیتابیس، شبکه یا حتی اتوموبیل) با هدف دستیابی به بهترین عملکرد ممکن تحت محدودیتهای معین هست.
مروری بر مبحث دیتابیس
دیتابیس چیست؟ دیتابیس مثل یک کمد بایگانی بزرگ هست، البته الکترونیکی و به جای اسناد کاغذی، اطلاعات دیجیتالی رو ذخیره میکنه. یک دیتابیس، ذخیره، مدیریت و بازیابی اطلاعات رو انجام میده. دیتابیس در اصل یک نرم افزار هست و روی یک کامپیوتر اجرا میشه که به این کامپیوتر سرور میگن. البته ممکنه به مجموعهی دیتابیس، سرورها و شبکه ای که سرور هارو بهم وصل میکنه هم بگن دیتابیس. حالا بیایید به دو دسته اصلی دیتابیس که با اونها مواجه میشیم بپردازیم.
مقایسه SQL و NoSQL
دیتابیس SQL که به عنوان دیتابیس رابطهای (Rational) هم شناخته میشه، اطلاعات رو در جدولها ذخیره میکنه. جدول ها دارای سطر و ستون هستند و هر جدول میتونه با جدول های دیگه دارای رابطه باشه.
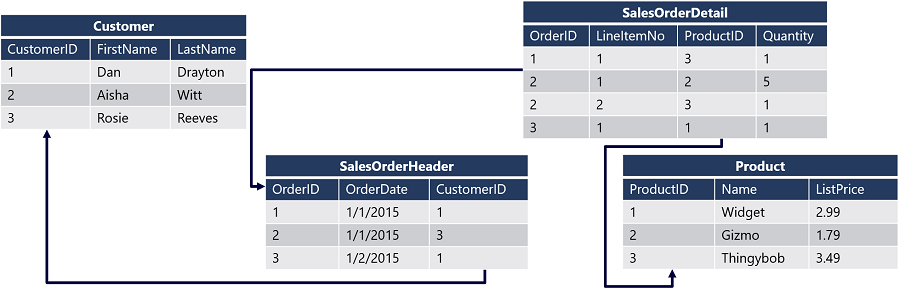
در دیتابیس NoSQL انعطاف پذیری بیشتری داریم، به این معنی که میتونیم داده ها رو در قالب های مختلفی مثل:
- document
- Key-Value pairs
- graph
- wide column
ذخیره کنیم.
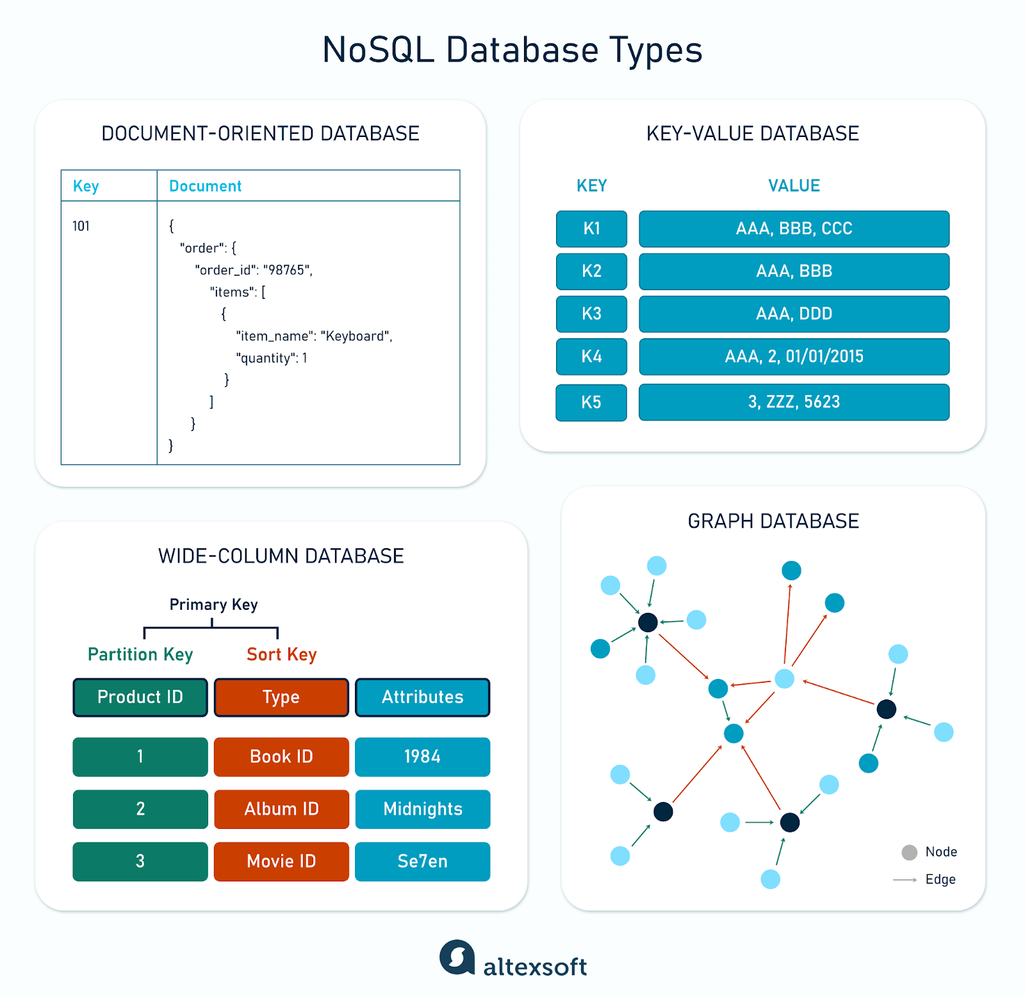
هر کدوم از این دو مدل دیتابیس، مزایا و معایب خودشون رو دارن، اما توی خیلی از پروژه ها نیازی نیستش که یکی رو به اون یکی دیگه ترجیح بدیم و بهترین کار اینه که ترکیبی از هر دو رو استفاده بکنیم.
| جنبه ها | SQL | NoSQL |
|---|---|---|
| نوع | رابطه ای | غیر رابطه ای |
| داده ها | ساختار یافته | ساختار یافته، نیمه ساختار یافته و بدون ساختار |
| طرحواره (schema) | ایستا | پویا |
| مقیاس پذیری | عمودی | افقی |
| Transactions (تراکنش ها) | ACID | Eventual consistency |
| انعطاف پذیری | کمتر | بیشتر |
| زبان | Structured Query Language (SQL) | زبان های مختص هر دیتابیس NoSQL |
| موارد استفاده (Use cases) | مناسب برای Query ها و تراکنش های پیچیده | مناسب برای توسعه سریع و مقیاس پذیری |
| نمونه ها | MySQL, PostgreSQL, Oracle, SQLite | MongoDB, Cassandra, Redis, Elasticsearch |
استفاده ی همزمان از SQL و NoSQL در یک پروژه، یک روش قدرتمند هست که اغلب به عنوان polyglot persistence شناخته میشه و یک رویکرد طراحی هست، که از نقاط قوت هر نوع دیتابیس برای مدیریت انواع مختلف داده ها و کارها استفاده میکنه. البته که این روش برای پروژه های بزرگ هست و به درد پروژه های کوچیک نمیخوره.
Performance tuning از دید کلی
Performance tuning فرایند بهینه سازی یک سیستم برای بالاترین سطح کارایی هست. برای مثال یک BMW GTR M3 رو در نظر بگیرید. این ماشین در حالت عادی هم فوق العاده هست، ولی اگر هدف ما شرکت در مسابقات باشه، باید یکسری تغییرات رو روی ماشین انجام بدیم. مثلا گذاشتن تایر هایی که اصطکاک کمتری دارن و یا افزایش قدرت موتور. البته توجه کنید با اینکه این تغییرات برای مسابقه عالی هستند، اما برای شرایط عادی اصلا خوب نیستن، برای مثال تایر ها باید میزان اصطکاک استانداردی داشته باشن تا ماشین امنیت لازم رو داشته باشه و صدای موتور نباید شهروند ها رو اذیت بکنه، ضمن اینکه این تغییرات، هزینه نگهداری خیلی بالاتری داره و این یعنی هزینه برای چیز هایی که شاید هیچ وقت استفاده نشن.
تصویر یک BMW GTR M3 قبل و بعد از Performance tuning :

Performance tuning در دیتابیس فرایندی هست که همه چیز، از بهینه سازی Query ها گرفته تا مدیریت منابع سخت افزاری رو پوشش میده و این یک کار یکباره نیست، بلکه یک فرایند مداوم هست که شامل نظارت، تشخیص و اصلاح رفتار سیستم میشه، همونطور که درمورد مسابقات اتوموبیل رانی همچنین چیزی داریم.
به طور خلاصه میشه گفت که Performance tuning در دیتابیس به این دلایل اهمیت داره:
- سرعت : کاهش زمان اجرای Query ها
- مقیاس پذیری : مدیریت کاربران با افزایش حجم کار
- بهره وری منابع : بهینه سازی استفاده از CPU، حافظه و ...
که هر کدوم از اینها میتونه با تغییراتی در معماری نرم افزار یا سخت افزار به دست بیاد. من در ادامه توضیحات خیلی کلی ای میدم ولی اگر قرار باشه که این موضوع به خوبی یاد گرفته بشه و در عمل هم پیاده سازی بشه، باید رفت سراغ منابع مرجع، مثل این کتاب :

Performance tuning در SQL در سطح نرم افزار
بهینه سازی Query ها :
- باز نویسی Query ها : نوشتن نام ستون های مورد نیاز به جای استفاده از * SELECT
- ابزار های اتوماتیک : استفاده از ابزار هایی برای تجزیه و تحلیل نحوه اجرای Query ها و شناسایی گلوگاه ها
استراتژی های Index گذاری :
- ایجاد Index های مناسب : Index کردن ستون هایی که مکررا از آنها استفاده میشود
- بررسی متناوب Index ها : بررسی متناوب Index ها تا برنامه بهینه بماند
کانفیگ کردن دیتابیس :
- تنظیم پارامتر ها : تغییر فایل های پیکربندی برای تخصیص حافظه مناسب، اندازه حافظه پنهان و تنظیمات ورودی-خروجی دیسک
- Connection pooling : تکنیکی برای مدیریت بهینه دسترسی به دیتابیس
مکانیزم های ذخیره سازی :
- ذخیره سازی نتایج (Result caching) : ذخیره نتایج Query های رایج
- ذخیره سازی حافظه : ذخیره کردن داده های پر کاربرد روی دیتابیس های دیگر، تا روی دیتابیس اصلی فشار کمتری بیاد
Performance tuning در SQL در سطح سخت افزار
ارتقا دادن اجزای مختلف :
- هارد : استفاده از هارد SSD به جای HDD برای دسترسی سریعتر به داده ها
- رم : برای پردازش سریعتر
- CPU : سی پی یو های چند هسته ای یا سریعتر برای افزایش سرعت و پردازش های پیچیده
پیکربندی های سرور (Server configuration) :
- متعادل سازی بار (Load balancing) : توزیع بار Query ها بین چندین سرور
Performance tuning در NoSQL در سطح نرم افزار
تقسیم بندی :
- تقسیم بندی افقی (Horizontal Scaling) : توزیع داده ها بین چندین سرور برای مدیریت بار و بهینه سازی سرعت دسترسی
- تکرار و ثبات (Replication and Consistency) : داده ها با چه سرعتی در میان سرور های دیگر توزیع شوند
- کلید های تقسیم بندی (Shard keys) : انتخاب کلید های تقسیم بندی خوب تا داده ها رو به صورت مساوی تقسیم کنه و از الگو های جستوجو پشتیبانی کنه
- ذخیره سازی (Caching) : درست همانند SQL، ذخیره سازی داده های پر کاربرد به گونه ای که دسترسی به آنها بهینه باشد
مدل سازی داده ها و طراحی طرحواره (Data Modeling and Schema Design) :
- انتخاب data model مناسب : متناسب با شرایط، یک data model انتخاب میکنیم
- طرحواره منعطف (Flexible Schema) : سازماندهی اطلاعات به شکلی که پیدا کردن چیزی که دنبال اش هستیم سریع باشه
- غیر نرمالسازی (Denormalization) : بر اساس درخواست های کاربران، لیست هایی درست میشود ( ساخته شده از ترکیب چند لیست ) که ممکن است در آن اطلاعات تکراری باشد، اما از آنجا که پر کاربرد هست، سرعت سیستم بالا میره
Performance tuning در NoSQL در سطح سخت افزار
- بهینه سازی گره (نود) های توزیع شده : هر نود در یک خوشه (Cluster) باید متعادل باشد
- عملکرد شبکه (Network performance) : از آنجایی که داده ها در محیط های NoSQL اغلب در چندین سرور یا حتی مراکز داده (Data center) پخش میشوند، شبکه میتواند تأثیر قابل توجهی داشته باشد
- تکثیر و تقسیم بندی (Replication and Sharding) : دیتابیس های NoSQL اغلب از Replication برای پخش داده ها در نود ها و از Sharding برای تقسیم بندی و اطمینان از در دسترس بودن داده ها استفاده میشود.
تا اینجای کار، مواردی از تنظیم عملکرد در دیتابیس رو به صورت خلاصه گفتم. در ادامه مواردی رو هم از تنظیم عملکرد در شبکه میگم چون همونطور که قبلا هم اشاره کردم، مثلا در مورد Replication و Sharding، ما نیاز به ارتباط بین نود های مختلف رو داریم پس اینجا نقش شبکه پر رنگ تر میشه. اما قبل از اینکه در مورد شبکه بخوام مثال هایی از تنظیم عملکرد بزنم، فکر میکنم خوب باشه تا Replication و Sharding رو یکم بیشتر توضیح بدم. فقط توجه کنید که ما این روش رو در SQL و یا ترکیبی از SQL و NoSQL هم به نحوی میتونیم داشته باشیم.
Replication و Sharding
Sharding و Replication، هر دو استراتژی های اساسی در دیتابیس های NoSQL هستند و اهداف متمایزی رو در نحوه مدیریت و مقیاس پذیری داده ها ارائه میدن.
Replication
Replication، چندین کپی از داده های مشابه رو در سرور ها (نود ها) ایجاد میکنه. هدف اصلی تضمین دسترسی بالا و تحمل خطا هست. اگر یک نود از کار بیوفته، نود های دیگه، داده های مشابه رو دارن و میتونن به ارائه Query ها ادامه بدن. با این روش انعطاف پذیری سیستم در مواجهه با خرابی های سخت افزاری یا مشکلات شبکه به طور چشمگیری زیاد میشه.
ملاحظات مربوط به سازگاری : عملیات هایی مثل حذف اطلاعات باید در بین کپی ها به صورت همزمان یا غیر همزمان همگام سازی بشه.
Sharding
Sharding یک مجموعه داده بزرگ رو به بخش های کوچک تر و قابل مدیریت تر به نام Shard تقسیم میکنه. با این کار سیستم میتونه بار کار رو روی گره های زیادی پخش بکنه و توان عملیاتی رو بالا ببره.
ملاحظات مربوط به مدیریت Query های پیچیده : Query هایی که یک Shard خاص رو هدف قرار میدن، سریع هستن، اما Query هایی که چندین Shard رو پوشش میدن، ممکنه پیچیدگی هایی رو به سیستم اضافه بکنن.
Performance tuning در شبکه
- بهینه سازی پهنای باند (Bandwidth Optimization) : تنظیم میزان داده ای که میشه از طریق شبکه ارسال کرد
- کاهش تأخیر (Latency Reduction) : پیکربندی پروتکل های مسیریابی برای انتخاب مسیر بهتر، یعنی کاهش تعداد hop ها بین مبدأ و مقصد
- تنظیم سخت افزار (Hardware setup): استفاده از ابزار های شبکه که کیفیت بالایی دارند و تنظیم درست این ابزار ها
آیا Performance tuning همیشه انجام میشه ؟
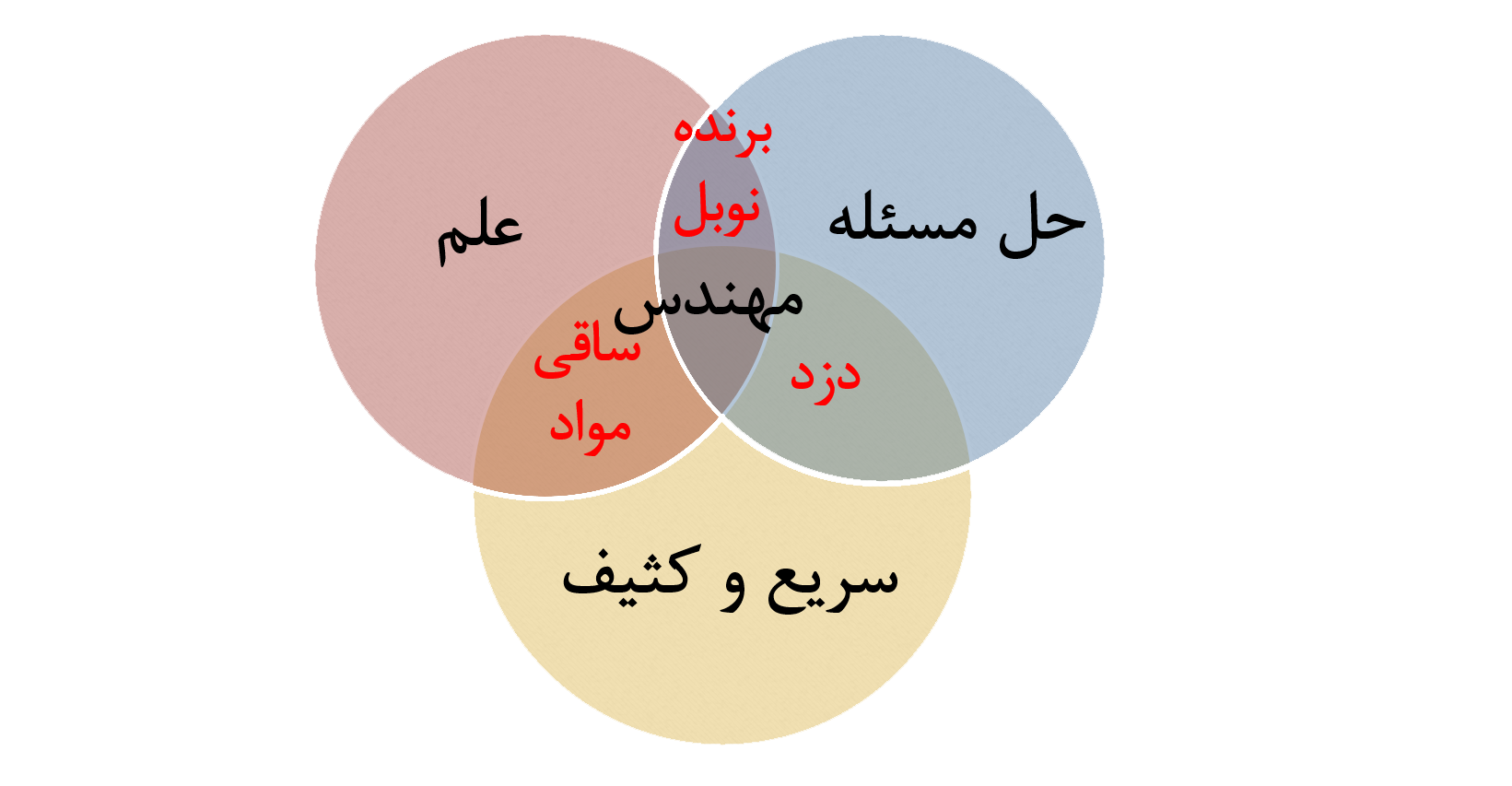
تصویر بالا یک نمودار ون برای توصیف یک مهندس هست، هر مهندسی. مطابق با این نمودار، مهندس ها باید کارهاشونو سریع و کثیف انجام بدن. اما این کار باعث به وجود اومدن هزینه های زیادی در دراز مدت و یا حتی در کوتاه مدت میشه، پس باید سعی کرد از همون اول اصولی رفت جلو.